In Brandient, we create names — many names — and each public-facing brand name has been eventually picked out of one or more lists of final candidates. Each list of final brand name candidates is voted out of large lists of candidates, that are just the final stage of each namer’s massive working lists. That’s a lot of names.
Each one needs internet domains clearance.
For quite some time now — and, from March 2008, when its first version entered service, is quite some time — I’ve been developing and maintaining Namejack, the domain checker that we use in Brandient to quickly assess the availability of internet domains for the names we create.
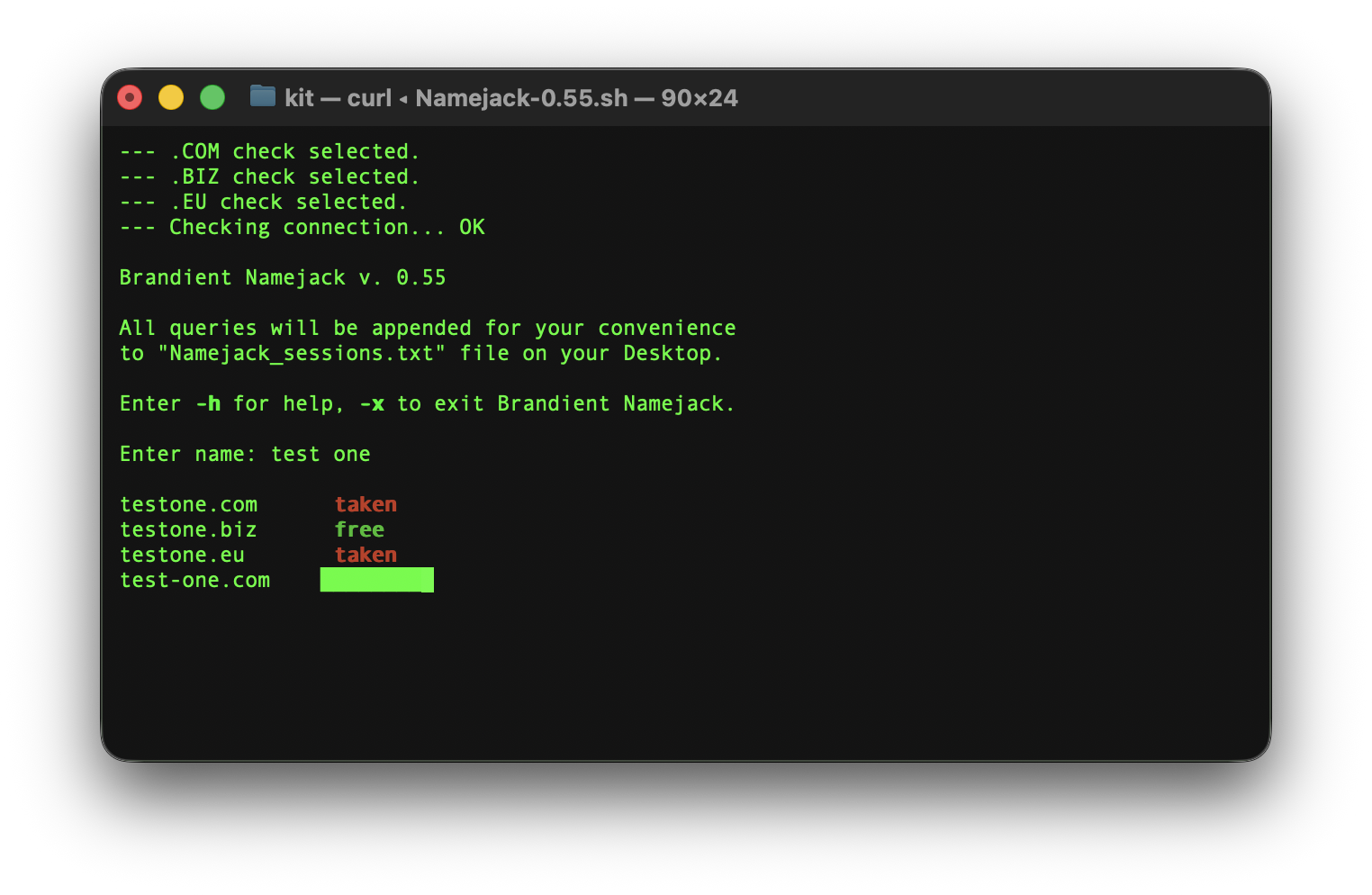
Namejack started as an interactive Bash script using quick and dirty tricks to establish domain availability. Over time it slowly gained batch modes, classical prefixes and suffixes treatments, rate limits, parking, for sale evaluations and so on, in both Bash and AppleScript.
In 2021 I decided to migrate it to Swift and offer it a GUI to make it more friendly and fast. SwiftUI looked easy to learn, at least for migrating the basic features of Namejack, so I started to mock up the app’s backbone while learning Swift and SwiftUI.
I wasn’t prepared for the complexity I encountered, at all. I thought — hey, it’s only about typing a name in and getting an availability evaluation, with reliable precision and decent speed.
Let’s unpack those “reliable precision” and “decent speed”.
When a user types a single brand name into Namejack, they initiate a cascade of discrete network operations — but a list of 200 names triggers a network tsunami and things get real serious, real fast.
Some name candidates comprise not one but two domain variants (concatenated and hyphenated forms), that must be checked across a number of TLDs spanning commercial extensions, country codes, and industry-specific domains. Each domain requires verification through multiple protocol layers — DNS resolution racing across several providers, WHOIS queries to legacy registries, RDAP requests for structured registration data, and HTTP probes to determine whether resolved addresses host actual content or parking pages. A single session can trigger thousands or more individual operations, many of which must execute with sub-second perceived latency to remain usable.
These operations cannot proceed sequentially (it would take hours, if not days, to process with a high degree of certainty a list of, say, 200 candidates), yet unrestricted parallelism would overwhelm both the device and remote servers. Namejack employs Swift’s actor model to achieve thread-safe concurrency without manual locking, with each subsystem — DNS resolution, WHOIS parsing, RDAP decoding, HTTP analysis, parking detection — operating within its own isolated boundary. Bounded worker pools with async channel backpressure prevent resource exhaustion, while registry-specific rate limiters (Verisign allows roughly five queries per second; some ccTLD registries permit only one, with brutal twenty-four-hour blocks for violations) enforce exponential backoff with staggered jitter to prevent thundering herd problems. Results stream to the interface immediately as each protocol layer responds, so users see DNS results within milliseconds while deeper WHOIS and RDAP intelligence populates asynchronously in the background.
The internet itself presents an often bizarre and chaotic environment, with innumerable — and many surprising — edge-cases. Corporate firewalls block non-standard ports and intercept DNS traffic, requiring multi-layer fallback cascades from encrypted DNS-over-HTTPS through plain UDP to cloud worker delegation. WHOIS responses vary wildly by registry — Verisign, DENIC, AFNIC, and others each implement their own formats with different field names, date formats, and character encodings — while post-GDPR privacy redaction renders much contact data useless, sometimes replaced by sales pitches masquerading as registrant names. A minority of RDAP servers use HTTP instead of HTTPS and many countries are slow to even migrate to RDAP (hello, Romania). Edge cases abound: servers returning HTML instead of text, sixty-second timeouts where two seconds is standard, mixed character encodings within single responses, captchas injected into WHOIS output, and circular referrals between registry and registrar that never resolve. The architecture must parse all of these reliably, extract whatever useful data exists, and gracefully degrade when authoritative sources fail.
Security concerns compound the complexity. Domain research involves connecting to unknown, potentially hostile endpoints — some domains resolve to IP addresses hosting malware distribution, phishing infrastructure, or aggressive parking pages designed to capture user data through tracking pixels, browser fingerprinting, and forced redirects to malicious destinations hosting illegal content, scams, scareware and anti-virus software subscriptions, or malware. Namejack implements pre-flight security screening using Google Safe Browsing’s local hash database before any content fetching, with suspicious domains delegated to isolated cloud workers for sandboxed analysis. Parking detection employs weighted heuristic scoring across DNS signals (known parking registrars, suspicious nameserver patterns), HTTP response indicators (redirect chains, monetization headers), and content analysis (keyword-stuffed links, affiliate density, minimal unique text) to distinguish legitimate websites from parked domains awaiting resale.
All of this machinery serves a singular purpose: delivering instant, accurate results while appearing effortlessly simple. A cache-first architecture serves all queries from persistent local data by default, with network operations occurring only on explicit user request — enabling offline functionality, sub-ten-millisecond response times, and complete domain evolution history for client presentations. What the user sees is a clean list of names with colored availability indicators; beneath the surface lies a sophisticated distributed system navigating rate limits and network hostility, defending against security threats, racing for latency across multiple protocols, and streaming results in real time through actor-isolated concurrency — the hidden complexity required to answer a deceptively simple question: “Is this name available?”
I was unaware of that — any of it! I had to learn it, hack it, and make it work. Initially, I did it by hand. Later, as the complexity exploded, I had to start using Claude and to design a whole zoo of expert agents.
And that was before getting to the linguistic analysis stack.